
ISO/IEC JTC 1/SC34 N0299
| Title: | The Standard Application Model for Topic Maps |
| Source: | Lars Marius Garshol, Graham Moore, JTC1/SC34 |
| Project: | ISO 13250 |
| Project editor: | Steven R. Newcomb, Michel Biezunski, Martin Bryan |
| Status: | Editor's draft |
| Action: | For review and comment |
| Date: | 2002-05-02 |
| Summary: | |
| Distribution: | SC34 and Liaisons |
| Refer to: | ISO/IEC JTC 1/SC34 N0229 |
| Supercedes: | ISO/IEC JTC 1/SC34 N0229 |
| Reply to: | Dr. James David Mason (ISO/IEC JTC1/SC34 Chairman) Y-12 National Security Complex Information Technology Services Bldg. 9113 M.S. 8208 Oak Ridge, TN 37831-8208 U.S.A. Telephone: +1 865 574-6973 Facsimile: +1 865 574-1896 E-mailk: mailto:[email protected] http://www.y12.doe.gov/sgml/sc34/sc34oldhome.htm Ms. Sara Hafele, ISO/IEC JTC 1/SC 34 Secretariat American National Standards Institute 25 West 43rd Street New York, NY 10036 Tel: +1 212 642-4937 Fax: +1 212 840-2298 E-mail: [email protected] |
This document defines the structure and interpretation of topic map information by defining the semantics of topic map constructs using prose, and their structure using a formal data model. This specification supersedes [ISO13250] and [XTM]. It is intended to become part of the new ISO 13250 standard.
This is $Revision: 1.15 $.
1 Introduction
2 The metamodel
3 Information item
types
3.1 Locator
items
3.2 Source
locators
3.3 The topic map
item
3.4 Topic
items
3.4.1
Establishing subject
identity
3.4.2
Topic
characteristics
3.4.3
Scope
3.4.4
Classes
3.4.5
Reification
3.4.6
Formal properties
3.5
Base name items
3.6
Variant items
3.7
Occurrence items
3.8
Association items
3.9
Association role items
4 Merging
4.1
Merging topics
4.2
Merging base
names
4.3 Merging topic
maps
4.4 Merging other
information items
5 Published
subjects
5.1 The class-instance
relationship
5.2 The
superclass-subclass relationship
5.3
Variant name scopes
6 Conformance
Topic maps are abstract structures which encode information about a domain and connect this information to information resources that are considered relevant to the domain. Topic maps are organized around topics, which are symbols representing real-world things, associations representing relationships between the things, and occurrences, which connect the topic map to information resources pertinent to the topics.
Topic maps may be represented in many ways: using topic map syntaxes in files, stored in databases, as internal data structures in running programs, and even mentally in the minds of humans. All these forms are different ways of representing the same conceptual structure, and it is this structure that is defined in this document, in the form of a data model.
It is expected that topic map implementations will have internal representations of topic map information that have a well-defined correspondence to the model defined in this document. This specification also defines a number of structural constraints and operations on the model, which implementations are expected to conform to.
A topic map processor is any software module that can process topic map information in conformance with this standard. It is assumed that the topic map processor does its work on behalf of another module known as the topic map application.
The process of exporting topic map information from such an internal representation to a topic map syntax is known as deserialization. The opposite process, that of building such a representation from information encoded using a topic map syntax is known as serialization. Specifications of topic map syntaxes are expected to define both processes in terms of the model specified in this document.
Distinguish between properties which have containment semantics, and which ones are references?
Should all types be called classes, all classes types, or should both terms be used? Which terms should be used where?
Ed. Note:(larsga)
Go through XTM 1.0: ensure consistency, and make notes about divergences. Ditto for ISO 13250:2000.
Ed. Note:(larsga)
Should we add more explanatory text with examples etc? Something along the lines of the "Gentle intro" of XTM 1.0?
The metamodel used in this document is the same as that used by the XML Information Set [infoset]. A topic map's information set consists of a number of information items, each representing some part of the topic map. The information item's properties contain the information recorded about that part of the topic map. Every topic map information set must contain exactly one topic map information item.
Throughout this document the term "information item" is used to refer to information items in general, while particular information item types are referred to as "topic items", "base name items", and so on.
The properties of information items may not only contain other information items, but also instances of the following types:
Strings are sequences of abstract Unicode characters [unicode].
Strings are considered equal if they consist of the exact same sequence of abstract Unicode characters. This implies that all comparisons are case-sensitive.
The text as written implies that processors must use a Unicode normalization form, without requiring any particular one. The Web Character Model requires Normalization Form C, as does the current XML 1.1 Working Draft. Requiring normalization improves string comparison, but imposes a possibly unwelcome burden on implementors.
A good source of information is Character Model for the World Wide Web 1.0, section 4.
Sets are collections of unordered values that contain no values considered to be equal to each other. This implies that attempts to add values already in a set will not cause the set to change.
Two sets are considered equal unless there exists a value in one set for which no equal value can be found in the other.
Ed. Note:(larsga)
Should we make merging (inside TMs) the procedure by which duplicates are removed from sets? Seems good to me, since we need this for both topics and base names.
The null value is used to indicate that properties have no value. It is distinct from the empty string and the empty set.
Null is only considered equal to itself.
Certain properties in the model are specified as computed properties, which means that they are specified in terms of a procedure by which their values may be gathered from other properties in the model. This reflects that while the properties are conceptually present they are strictly redundant.
Throughout the specification UML diagrams [UML] are used in addition to the infoset formalism for purposes of illustration. These diagrams are purely informative, and in cases of discrepancy between the diagrams and the prose, the prose is definitive.
The Standard Application Model for topic maps is defined as the set of information item types and their properties presented in this section.
An information resource is a resource that can be represented as a sequence of bytes, and thus could in theory be retrieved over the network. Topic maps can refer to information resources external to themselves in order to make statements about them. These information resources are not part of the topic map, but only referenced from it.
A locator is a string, an addressing expression that references one or more information resources. Locators are always expressed in some notation, which defines their formal syntax and interpretation. The definition of locator notations is outside the scope of this specification.
Must locators really refer to information resources? Some URN schemes allow resources that are not information resources to be addressed. Do the two preceding paragraphs need to take this into account?
Issue (locator-normalization):
If a locator syntax allows equivalent locators to be given different syntactical expressions normalization must be applied in order to take this into account. Where should the text that sets out this requirement go? Does it belong in this document, or in the syntax specifications?
In this model locator items represent locators and serve as the connection point between the topic map and the information resources it describes. Locator items may have the following properties:
[notation]: A non-empty string. The string is the name
of the notation used by this locator. If the string is "URI" the notation is that described in [RFC2396]. If
not, the two first characters of the string must be "X-"; all other values are reserved.
[reference]: A non-empty string. The string is the actual locator, whose interpretation and syntax is governed by the value of the [notation] property.
Locator information items are equal if they have the same values in their [notation] and [address] properties.
The source locators of an information item may be used to refer to the information item, either from other information items, or from outside the topic map. When a topic map is created through deserialization from some topic map syntax source locators are created that point back to the syntactical constructs that gave rise to the information items. Information items may also have source locators assigned to them by means not constrained by this specification, in order that they may be referred to from outside (or within) the topic map.
Source locators are used in this specification to define reification, in the syntax specifications to ensure that information loaded from different information resources is correctly collated, and it is expected that other specifications and technologies will use them to define mechanisms for referencing topic map constructs.
It is an error for two different information items to have locator items that compare as equal in their [source locators] properties.
A topic map is a collection of topics and associations, which may be represented in many forms. Its purpose is to convey information about subjects through the assignment of characteristics to topics representing those subjects. The topic map itself has no meaning or significance beyond its use as a container for the information about those subjects; in particular, the topic map itself does not represent anything.
There is exactly one topic map item in each information set, and all information in the set is available from the properties of that item. Every topic map item represents a topic map.

Topic map items have the following properties:
[source locators]: A possibly empty set of locator items. This is the source locators of the topic map.
[topics]: A possibly empty set of topic items. This is the set of all the topics in the topic map.
[associations]: A possibly empty set of association items. This is the set of all the associations in the topic map.
[reifier]: A topic item, or null. The topic item is the topic that reifies this information item.
The value of the property can be computed as follows: if there exists a topic item in whose [subject indicators] property can be found a locator item equal to one in the [source locators] property of this information item that topic item is the value of this property. If not, the value is null.
There is no defined procedure for comparing topic map items.
Should topic map items have a [schema] property that may contain their schema definition(s)? This would make it clear where to find the topic map schema. On the other hand, the TMCL specification should perhaps have its own rules for specifying how to find the schema of a topic map. It may be better to keep the levels strictly apart.
A subject is anything that has identity. In the most generic sense, a subject is anything whatsoever, regardless of whether it exists or has any other specific characteristics, about which anything whatsoever may be asserted by any means whatsoever. In particular, it is anything on which the creator of a topic map chooses to discourse.
The standard makes the following assumptions about subjects:
Subjects are atomic, meaning that a subject is conceptually a single thing. That thing may be divisible into smaller components, but it is still a single thing. That is, to speak of two things is to speak of two subjects. To speak of a group consisting of two things is to speak of a single thing, which is the group—or possibly three: the group, and its two members.
Subjects are identifiable, meaning that not only do subjects have identity, but their identity can also be established. Two mechanisms are provided for the purposes of establishing subject identity, one of which is formal, while the other is informal.
Subjects are persistent, meaning that while a physical subject may disappear the subject still has identity in the sense that we may continue to speak of it. For example, the halibut William Cowper ate is long gone [cowper], but it is still possible to make statements about it, and so it is still a subject.
Subjects are independent of perspective, meaning that while there may be different points of view on what something is each point of view is a subject in its own right. So while Plato speaks of 'the good' his notion of it is clearly a different subject from 'the good' of John Stuart Mill. For this reason topics have no scope; there is no limit to their validity as notions.
Should the standard say as little as possible about the nature of subjects, or should it be more detailed in order to provide guidance to readers? The current text is detailed, but may be too much so.
Should the standard state outright that "subject" and "resource" (as per RFC 2396) are the same thing? (Quote: "A resource can be anything that has identity. Familiar examples include an electronic document, an image, a service (e.g., "today's weather report for Los Angeles"), and a collection of other resources. Not all resources are network "retrievable"; e.g., human beings, corporations, and bound books in a library can also be considered resources."
A topic is a symbol used within a topic map to represent some subject, about which the creator of the topic map wishes to make statements. Topics only exist in order to act as proxies for the subjects they represent, in order to allow statements to be made about the subjects through the assignment of characteristics to the topics that represent them.
Every topic represents one, and only one, subject. The process of merging ensures that whenever two topics are known to represent the same subject they are merged automatically. It may well be, however, that two topics may represent the same subject without this being detected by the rules of this standard. The merging of topics is therefore disallowed only when it is clear that they must represent different subjects.
Issue (term-subject-identity):
Is the term "subject identity" needed? It is defined in XTM 1.0, but it is not clear that there is any use for it.
A subject indicator is an information resource that is referred to from a topic map in order to unambiguously identify the subject of a topic to a human being. Any information resource can become a subject indicator by being referred to as such from within some topic map, whether or not it was intended by its publisher to be a subject indicator. A subject identifier is a locator that refers to a subject indicator.
A subject address is a locator that refers to the information resource that is the subject of a topic. The topic thus represents that particular information resource. Different locators are considered to address different information resources.
Ed. Note:(larsga)
Add examples to make this more understandable.
The term "subject address" does not correlate with the term "subject indicator", since "subject address" corresponds more clearly to "subject identifier". A better name should be found.
Issue (term-subject-address-def):
At what level of interpretation does the topic represent the resource? Does it represent that storage location? The stream of bytes? The stream of bytes interpreted in some particular way? The standard must either leave the details open or clarify this. Note that it may be impossible to clarify when the interpretation of locators is left undefined.
Merging in topic maps is defined in terms of subject identifiers and subject addresses.
Base names, occurrences, and association roles are collectively known as topic characteristics, as they are the only characteristics topics may have in a topic map. A topic characteristic assignment is the containment of an information item representing a topic characteristic in a property of a topic item. Any topic characteristic assignment is a statement about the subject the topic represents.
The properties of topic items that do not represent topic characteristics are not statements about the subject; they are statements about the topic. As such they are part of the topic map machinery, and not formal statements about the subject.
All topic characteristic assignments have a scope, which defines the extent to which the statement represented by the assignment is valid. Outside the context represented by the scope the statement is not considered valid. Formally, a scope is composed of a set of subjects that together define the context. That is, the statement is considered valid only in contexts where all the subjects in the scope applies. In a sense, the scope is made up of the union of the subjects it is composed of.
If the scope of a topic characteristic assignment is the empty set the statement is considered to have unlimited validity, and it is said to be in the unconstrained scope.
Precisely how a subject defines a context is not constrained by this standard, but left for those creating topics representing subjects used in scopes to define as part of the definition of their subjects.
Examples of the use of scope are given below:
The term "Suomi" is the name of Finland in the context of Finnish. This corresponds to assigning the base name "Suomi" to a topic representing Finland, and giving it as scope a topic representing Finnish.
According to Norman Davies World War II started on June 6, 1937 [Davies]. This corresponds to creating a topic reprsenting WWII, and assigning to it the string "June 6, 1937" as an occurrence of type "start date", and giving this occurrence as scope a topic representing the person Norman Davies.
A class is a set of individual subjects, each of which is an instance of the class. Classes are generally used to represent sets of subjects which share some commonality, but this specification does not restrict the possible uses of classes, or their meanings. A class may itself be an instance of another class.
The class-instance relationship is not transitive. That is, if A is a class of which B is an instance, and B is a class of which C is an instance, it does not follow that C is an instance of A.
Ed. Note:(larsga)
Should this be moved to the published subjects section, if we remove the [classes] property?
Ed. Note:(larsga)
This text should be expanded on. Examples are necessary, as is more defining prose.
Every topic represents a subject, and if the subject is part of a topic map the relationship between the topic and its subject is one of reification. Reification is thus a special kind of representation.
The use of reification allows topics to be created that represent other topic map constructs, and this allows any kind of topic characteristic to be assigned to the topic map constructs by way of the topic that reifies the construct. For example, this allows associations to be given names, occurrences, and associations, and similarly for all other topic map constructs.
Formally, reification is done by giving the reifying topic a subject identifier that refers to the topic map construct that is being reified. In model terms, this means that if an information item has a source locator item that is equal to one of the subject identifiers of a topic, that topic item reifies the information item.
Note that one topic cannot reify another. If a topic refers to another by means of its subject identifiers this means that the two topics represent the same subject, and they will therefore be merged.
Ed. Note:(larsga)
Make sure we add text noting that reifying more than one topic map object is an error.
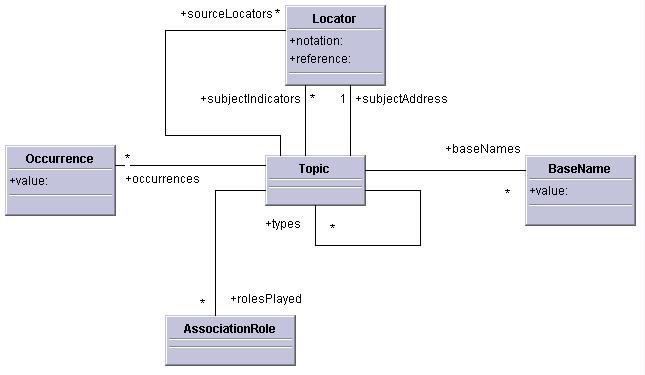
Topic items have the following properties:
[source locators]: A possibly empty set of locator items. This is the source locators of the topic.
[classes]: A possibly empty set of topic items. The topics represent the classes of which this subject is an instance.
[base names]: A possibly empty set of base name items. This is the set of base names assigned to this topic.
[occurrences]: A possibly empty set of occurrence items. This is the set of occurrences assigned to this topic.
[roles played]: A possibly empty set of association role items. This is the set of association roles played by this topic.
The value of this property can be computed as follows: it is the set of all association role items whose [role playing topic] property contains this topic item.
[subject indicator]: A possibly empty set of locator items. The locator items refer to the subject indicators of this topic.
[subject address]: A locator information item, or null. The locator, if present, refers to the information resource that is the subject of this topic.
[reified]: an information item, or null. This is the information item that is reified by this topic item; that is, the topic map construct that is the subject of this topic.
The value of this property can be computed as follows: if any information item has in its [source locators] property a locator item equal to on in the [subject indicators] property of this topic item, that information item is the value of this property. If not, the value is null.
Two topic items are considered equal if they, when present in the same information set, are required to be merged, according to the rules of 4.1 Merging topics. If not they are not equal.
A base name is a name or label for a subject, expressed as a string. That is, it is something that identifies the subject (though not necessarily uniquely) and can be used as a label for the subject in user interfaces. The notion of a base name corresponds closely to the common sense notion of a name. Suitable base names for people, countries, and organizations are their names, while base names for documents, musical works, and movies might be their titles. Base names may have variant names, which are alternative forms of the name that may be more appropriate in some context.
Base names always have a scope, which defines in what contexts the base name is an appropriate label for the subject. A subject may have any number of base names, and the only basis for choosing which base name(s) to use in any given situation is their scope.
XTM 1.0 has a term "topic name", but it is not clear how it relates to the term "base name". Its use in XTM 1.0 seems to be inconsistent. Is the term useful, or should it be abandoned?

Base names items represent base names, and have the following properties:
[source locators]: A possibly empty set of locator items. This is the source locators of the base name.
[value]: A string, which may be empty, but not null. This string is the base name.
[scope]: A possibly empty set of topic items. This set is the scope that describes the validity of this base name as a label for the subject.
[variants]: A possibly empty set of variant items. This set is the variant names that are alternative forms of the base name.
[reifier]: A topic item, or null. The topic item is the topic that reifies this information item.
The value of the property can be computed as follows: if there exists a topic item in whose [subject indicators] property can be found a locator item equal to one in the [source locators] property of this information item that topic item is the value of this property. If not, the value is null.
Base name information items are considered equal if the values of their [value] and [scope] properties are equal.
A variant name is an alternative form of a base name that may be more suitable in certain contexts than the base name itself. The scope of the variant name is the only basis for establishing what variant name is most suitable in any given situation. A variant name may be a string, but it may also be any other kind of information resource.
When choosing a label for a topic applications are expected to select the base name they consider most appropriate, and then evaluate which of the forms of that base name is best suited for display in that particular context, which may be the base name or one of its variants. This standard does not constrain the process by which this is done.

Variant items represent variant names, and have the following properties:
[source locators]: A possibly empty set of locator items. This is the source locators of the variant name.
[value]: : A string, which may be empty, or it may be null. The string, if set, is the variant name. If it is not null, the [resource] property must be null.
[resource]: A locator item, or null. The locator, if set, refers to the information resource that is the variant name. If it is not null, the [value] property must be null.
[scope]: A non-empty set of topic items. This set is the scope that describes in what context(s) the variant name may be preferred as a label for the topic.
The value of the [scope] property of each variant item must be a true superset of the value of the [scope] property the base name item that is its parent.
[reifier]: A topic item, or null. The topic item is the topic that reifies this information item.
The value of the property can be computed as follows: if there exists a topic item in whose [subject indicators] property can be found a locator item equal to one in the [source locators] property of this information item that topic item is the value of this property. If not, the value is null.
Variant information items are considered equal if the values of their [value], [resource], and [scope] properties are equal.
An occurrence is a relationship between an information resource and a subject. The relationship between the information resource and the subject is described by the occurrence type, itself a subject, that is attached to the occurrence. Occurrences are generally used to connnect information resources with the subjects they are relevant to. Note that the occurrence is properly not the resource, but the relationship between it and the subject. The information resource may either be a string inside the topic map or an external resource.
All occurrences have a scope, which defines the contexts in which the occurrence relationship between the information resource and the subject is valid.
Issue (xtm-def-occurrence-type):
According to XTM 1.0 the default occurrence type is the "occurrence" published subject. Should this standard follow its lead? If so, what does it mean?
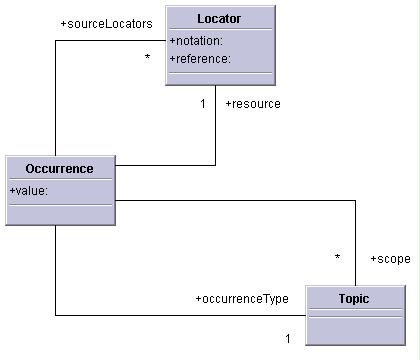
An occurrence item represents an occurrence and can have the following properties:
[source locators]: A possibly empty set of locator items. This is the source locators of the occurrence.
[value]: A string, which may be empty, or it may be null. The string, if set, is the information resource the occurrence connects with the subject. If it is not null, the [resource] property must be null.
[resource]: A locator item, or null. The locator, if set, is the information resource the occurrence connects with the subject. If it is not null, the [value] property must be null.
[scope]: A possibly empty set of topic items. This set is the scope that describes in what context the occurrence relationship may be considered valid.
[occurrence type]: A topic item, or null. The topic item represents the subject that defines the nature of the occurrence relationship.
[reifier]: A topic item, or null. The topic item is the topic that reifies this information item.
The value of the property can be computed as follows: if there exists a topic item in whose [subject indicators] property can be found a locator item equal to one in the [source locators] property of this information item that topic item is the value of this property. If not, the value is null.
Occurrence information items are considered equal if the values of their [value], [resource], [scope], and [occurrence type] properties are equal.
An association is a relationship between one or more subjects. Associations have an association type, a subject which describes the nature of the relationship. The involvement of each subject in the relationship is called its association role.
All associations have a scope, which defines the context in which the statement represented by the association can be considered valid. The scope applies to the association roles as characteristics of the topics they connect, but all association roles in an association have the same scope, and so the scope is considered to apply to the association as a whole as well.
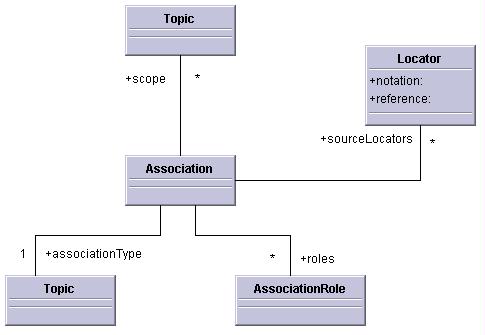
Association items represent associations, and may have the following properties:
[source locators]: A possibly empty set of locator items. This is the source locators of the association.
[scope]: A possibly empty set of topic items. This set is the scope that describes in what context the association may be considered valid.
[association type]: A topic item, or null. The topic item represents the subject that defines the nature of the relationship.
[roles]: A non-empty set of association role items. The association role items represent the association roles that make up this association.
[reifier]: A topic item, or null. The topic item is the topic that reifies this information item.
The value of the property can be computed as follows: if there exists a topic item in whose [subject indicators] property can be found a locator item equal to one in the [source locators] property of this information item that topic item is the value of this property. If not, the value is null.
Association information items are considered equal if the values of their [scope], [association type], and [roles] properties are equal.
An association role connects two pieces of information within an association: the subject participating in the association, known as the association role player, and the subject defining the nature of its participation, known as the association role type.
Ed. Note:(larsga)
Should we include examples to make this clear? Here, or under association?

Association role items represent association roles, and may have the following properties:
[source locators]: A possibly empty set of locator items. This is the source locators of the association role.
[role playing topic]: A topic item, or null. This is the topic item that represents the association role player.
[role type]: A topic item, or null. This is the topic item that represents the association role type.
[reifier]: A topic item, or null. The topic item is the topic that reifies this information item.
The value of the property can be computed as follows: if there exists a topic item in whose [subject indicators] property can be found a locator item equal to one in the [source locators] property of this information item that topic item is the value of this property. If not, the value is null.
Association role information items are considered equal if the values of their [role type] and [role player] properties are equal.
Merging is a process applied to topic maps in order to reduce the number of topics representing the same subject. This specification requires merging to be performed in certain cases, but these are insufficient to guarantee that there will be one topic per subject. Applications are therefore allowed to merge topics in cases where it is not clear that the topics represent different subjects.
Ed. Note:(gdm)
Should consider creating a new section called "Operations on the model", which deals with more than just merging. Merging would then be a part of this section.
Whenever two different topic items have
at least one equal locator item in their [subject indicators] properties,
at least one equal locator item in their [source locators] properties,
an equal locator item in their [subject address] property, or
an equal locator in the [subject indicators] property of the one topic item and the [source locators] property of the other.
they must be merged.
Merging of two topic items, A and B by following this procedure:
Create a new topic item C.
Replace A by C wherever it appears in one of the following properties of some information item: [topics], [classes], [scope], [occurrence type], [association type], [role player], and [role type].
Repeat for B.
Set C's [source locators] property to the union of the values of A and B's [source locators] properties.
Set C's [subject indicators] property to the union of the values of A and B's [subject indicators] properties.
If A or B has a value for the [subject address] property, set this as the value of C's [subject address] property.
Set C's [classes] property to the union of the values of A and B's [classes] properties.
Set C's [base names] property to the union of the values of A and B's [base names] properties, merging equal base name items in C's [base names] property according to the rules of 4.2 Merging base names.
Set C's [occurrences] property to the union of the values of A and B's [occurrences] properties.
Set C's [roles played] property to the union of the values of A and B's [roles played] properties.
If both A and B have a value in their [subject address] property and those values are different A and B cannot be merged. If A and B are required to be merged by the rules of this specification the topic map is invalid.
Ed. Note:(larsga)
We need a defined term for topic maps that contain errors. Also, we need a consistent policy for dealing with them. Obviously, the errors must be reported, but then what? Should there be a defined recovery procedure? It must work both for import, generation, human editing, and API modifications.
Base names are merged when the [base names] property of a topic item contains two equal base name items. The procedure for merging two base name items A and B is given below.
Create a new base name item C.
Set C's [source locators] value to the union of the value of the [source locators] properties of A and B.
Set C's [value] value to the value of the [value] property of A or B. If merging was triggered by the rules of this specification A and B should have the same rule. If not, applications may choose either value.
Set C's [scope] value to the value of the [scope] property of A or B. If merging was triggered by the rules of this specification A and B should have the same rule. If not, applications may choose either value.
Set C's [variant] value to the union of the [value] properties of A and B.
Ed. Note:(larsga)
Do we really need to bother about when merging is not triggered by the rules given here?
Topic map merging is an operation that given two separate topic maps produces a single topic map which contains all the statements made by the two source topic maps. This specification is not concerned with when topic map merging occurs, but specifies a minimal procedure for merging topic maps. Topic map processors are free to make additional merges based on extra information available to them.
Merging two topic maps A and B is done as follows:
Create a new topic map item C.
Set the [source locators] property of C to the empty set.
Set the [topics] property of C to the union of the [topics] properties of A and B.
Set the [associations] property of C to the union of the [associations] properties of A and B.
Apply merging to the [topics] property of C until no duplicates remain.
Apply merging to the [associations] property of C until no duplicates remain.
Other information items, except locator items, are merged whenever two equal items A and B are found in the value of some property. In all cases, the procedure is as follows:
Create a new item C of the same type as A and B.
Set C's [source locators] property to the union of the [source locators] properties of A and B.
For all other properties, give C the same value as A and B had.
A published subject indicator is a subject indicator that is published and maintained at an advertised location for the purposes of supporting topic map interchange and mergeability. A published subject is any subject for which there exists at least one published subject indicator. A published subject identifier is the subject identifier of a published subject indicator.
This section defines a number of published subjects in the expectation that many topic map applications will need them. These subjects form a central part of the topic map standard, yet there is no requirement that applications use them. Applications are free to define their own alternatives.
Ed. Note:(larsga)
Make sure we conform to the PubSubj TC guidelines (once they are in place).
Should the "topic", "association", and "occurrence" PSIs be specified here? If so, what do they mean, and what is their function?
Ed. Note:(larsga)
Specify the PSI here, but consider relation between this and the section above. Resolve what to do about the [classes] property before moving on here.
A class may be a subclass of another, which is then considered the superclass of the other. If B is the subclass of A, it follows that every instance of B is also an instance of A. The opposite it not necessarily true. The relationship between a superclass and its subclasses is known as the superclass-subclass relationship. A class may have any number of subclasses and superclasses. Scope applies to this association type in just the same way as it does to any other.
The superclass-subclass relationship is transitive, which means that if B is a subclass of A, and C a subclass of B, C is also a subclass of A.
The superclass-subclass relationship between two classes can be asserted in topic maps using an association item that conforms to the following rules:
The [association type] property must be set to a topic item
that has in its [subject indicators] property a locator item with [notation]
set to "URI" and [reference] set to "http://www.topicmaps.org/xtm/1.0/core.xtm#superclass-subclass".
The [roles] property must contain exactly two association role items.
One of the association items in the [roles] property must have
its [role type] property set to a topic whose [subject indicators] property is
set to a locator item with [notation] set to "URI" and [reference] set to "http://www.topicmaps.org/xtm/1.0/core.xtm#superclass". The [role player] property will then contain the topic item
representing the superclass.
One of the association items in the [roles] property must have
its [role type] property set to a topic whose [subject indicators] property is
set to a locator item with [notation] set to "URI" and [reference] set to "http://www.topicmaps.org/xtm/1.0/core.xtm#subclass". The [role player] property will then contain the topic item
representing the subclass.
The subject identifier http://www.topicmaps.org/xtm/1.0/core.xtm#sort (notation "URI"), identifies the notion of suitability of a variant name for use as a
sort key for a subject. A variant item that has a topic with this subject
identifier in its [scope] property represents a variant name intended to be
used as a sort key for the topic item it belongs to.
Does this standard need to define how sorting of topics is done? It is a highly fundamental operation. On the other hand, users may want flexibility in this regard.
The subject identifier http://www.topicmaps.org/xtm/1.0/core.xtm#sort (notation "URI"), identifies the notion of suitability of a variant name for use as a
display name for a subject. A variant item that has a topic with this subject
identifier in its [scope] property represents a variant name intended to be
used as a label for the topic item it belongs to. This published subject is
included only for backwards compatibility with ISO 13250:2000.
A topic map processor conforms to this standard provided it makes
all the information described in 3 Information
item types available to applications. Additional information may be
provided, but none may be left out. It is allowed to only allow locators that
follow the "URI" notation, and to represent these as strings.
It is not required that topic map processors treat computed properties differently from the other properties in any way.