ISO/IEC JTC 1/SC34 N0298
![]()
ISO/IEC JTC 1/SC34
Information Technology --
Document Description and Processing Languages
| Title: | A Draft Reference Model for ISO 13250 Topic Maps |
| Source: | Steven R. Newcomb and
Michel Biezunski Co-editors, ISO/IEC 13250 |
| Project: | ISO/IEC 13250 |
| Project editor: | Steven R. Newcomb, Michel Biezunski, Martin Bryan |
| Status: | Draft for review |
| Action: | |
| Date: | 4 April 2002 |
| Summary: | |
| Distribution: | SC34 and Liaisons |
| Refer to: | SC34 N244 |
| Supercedes: | SC34 N243 |
| Reply to: | Dr. James David Mason (ISO/IEC JTC1/SC34 Chairman) Y-12 National Security Complex Information Technology Services Bldg. 9113 M.S. 8208 Oak Ridge, TN 37831-8208 U.S.A. Telephone: +1 865 574-6973 Facsimile: +1 865 574-1896 E-mailk: mailto:[email protected] http://www.y12.doe.gov/sgml/sc34/sc34oldhome.htm Ms. Sara Hafele, ISO/IEC JTC 1/SC 34 Secretariat American National Standards Institute 25 West 43rd Street New York, NY 10036 Tel: +1 212 642-4937 Fax: +1 212 840-2298 E-mail: [email protected] |
A Draft Reference Model for ISO 13250 Topic Maps
Steven R. Newcomb and Michel Biezunski
Co-editors, ISO/IEC 13250
Introduction
The purpose of ontologies (sets of knowledge-bearing assertion types), taxonomies (classes of things, ideas, etc.), and vocabularies (such as markup vocabularies) is to allow the human members of communities of interest to communicate among themselves about the things with which their communities are concerned.
However, knowledge that is represented in the terms of a specific community may have high value outside its community of origin. How can distinct bodies of knowledge, created and maintained by distinct, non-cooperating communities, be made usefully available in contexts other than their communities of origin? One answer is to merge them with other bodies of knowledge, in conformance with the Reference Model of ISO 13250 Topic Maps.
Layers of Standardization
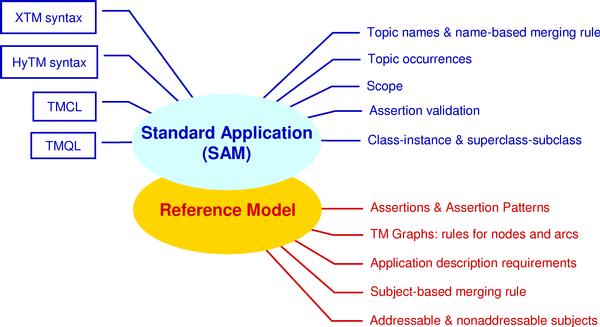
Syntax layer.The 13250 Standard provides two syntaxes for interchanging Topic Maps, one known as "HyTM" and one called "XTM". The HyTM syntax offers both flexibility and rigor by means of HyTime architectural forms. The XTM syntax was specifically designed for XML and the Web. Since there are multiple standard syntaxes, the question naturally arises: What is the nature of the information that is being interchanged by means of these syntaxes? There must be a layer of common meanings -- an ontology -- on which both of these syntaxes are based.
Standard Application layer.The set of generalizations on which both HyTM and XTM are based is called the "Standard Application" layer. The word "Application" is used here in an extremely broad sense; except for the Reference Model, the entire ISO 13250 Topic Maps Standard will describe a single Application called the "Standard Application". The Standard Application is a set of semantics for which a data model, the "Standard Application Model [SAM]", is also being developed. The Standard Application defines virtually all of the familiar features of the Topic Maps paradigm, including topic names, topic occurrences, and scopes. Instances of both the HyTM and XTM syntaxes say the same kinds of SAM-defined things, but in different ways, as a result of the different requirements that drove the design of each syntax. Additional SAM-centric languages are planned, including Topic Maps Query Language (TMQL) and Topic Maps Constraint Language (TMCL).
Non-ISO syntaxes, including proprietary syntaxes and community-specific syntaxes, such as NewsML, can be used to interchange SAM-conforming topic maps. In order that interchange and merging can occur reliably and predictably, the interpretation of each syntax in terms of the SAM and the Reference Model will have to be rigorously specified.
Reference Model layer.The set of generalizations on which the Standard Application, and all other Applications are based is called the "Reference Model". The Reference Model provides a robust and predictable basis for collating ("aligning" or "merging") knowledge about subjects, regardless of the diversity of the ontologies that govern the understanding of such knowledge.
From the perspective of the Reference Model, the Standard Application is an extensible ontology: it provides assertion types for such familiar Topic Maps features as topic names, topic occurrences, topic types, and scopes. Although it might seem appropriate for these features to be built into the fundamental layer of the Topic Maps standard, none of these assertion types appears in the Reference Model. Instead, they are in the Standard Application, in order to allow implementations of Applications other than the Standard Application to be based on different approaches to knowledge representation and management, without incurring the cost of supporting features of the Standard Application that may be irrelevant to their contexts of use.
 |
The draft Reference Model is designed to preserve the maximum possible flexibility for the design of Applications, while still providing a basis for predictable automated merging of diverse topic maps. Most of the familiar features of Topic Maps are found in the Standard Application, and not in the Reference Model.
Description of the Reference Model
In the draft Reference Model, a topic map is seen as a set of "assertions", no more and no less. Each assertion asserts the existence of a strongly-typed relationship between some specific set of subjects of conversation. Each such subject is a "role player" in the assertion; it plays a specific role in the relationship. The ontologies of Applications may include an unbounded number of kinds of assertions ("assertion types"). The roles, the role players, the assertions themselves, and the types of the assertions, are all regarded as subjects, and any of these features of an assertion can be role players in other assertions.
Every topic map is a graph, and every assertion within a topic map is a subgraph within that graph. According to the draft Reference Model, graphs of topic maps consist of "nodes" (also sometimes called "vertices" or "vertexes" or "topics") and four distinct kinds of "arcs" or "edges" that connect the nodes to one another. The Reference Model establishes a single graphic meta-structure for all assertions.
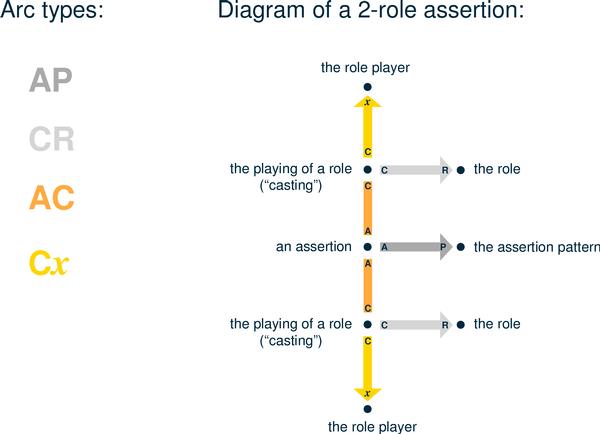 |
Fundamentally, the draft Reference Model is four arc types, here shown as differently-shaded bars. The names of the arc types are concatenations of their endpoints, e.g., the CR (casting-role) arc type has the endpoints C and R. Each arc type has a specific function in the representation of assertions. There are rules regarding the combinations of arc endpoints as which a given node can serve, but any node can serve as the x end of any number of Cx arcs. Nodes are shown here as dots. Each node (or "topic") is the unique surrogate of exactly one subject.
The Reference Model imposes certain redundancy-elimination and subject-collation requirements on Application implementations, so that everything that is known about a given subject turns out to be attached to the one and only node that corresponds to that subject. Every node represents exactly one subject, and it is connected by arcs to everything that is known about it in the topic map. Every arc is a component of exactly one assertion. Every node in a topic map graph serves as some combination of one or more of the eight end points of the four types of arcs. From this combination of endpoints, all of the assertions in which the node is involved -- as a role player and/or as an internal component of one or more assertions -- is fully and unambiguously specified.
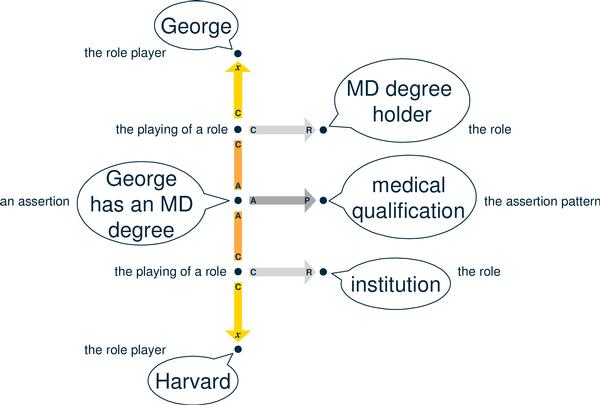 |
An instance of an assertion. In this diagram, the subject of each node is shown in a balloon. (Except for the casting nodes. The subject of the upper casting node is the fact that George is the player of the MD degree holder role in this particular assertion.)
The draft Reference Model defines two assertion types; these "paradigmatic" assertion types are the only ones that are certain to be found in the ontologies of virtually all Applications. These include:
-
Instances of the "assertionPattern-role-rolePlayerConstraints" assertion type are used to declare that assertion patterns (which, of course, are themselves subjects) include specific roles. Each role is a subject, and the set of constraints on players of a role, if any, is also a subject.
-
Instances of the "topic-subjectIndicator" assertion type is used to declare that subjects have subject indicators. (A subject indicator, considered as a piece of information, is itself a subject -- an "addressable subject" or "subject constituter".)
Features of the Draft Reference Model
Predictable merging.In the Topic Maps paradigm, information items that share a particular common meaning can all be connected by reference to any of an unlimited number of "subject indicators" and/or "published subject indicators", each of which is a piece of addressable information that independently serves as a surrogate for that particular common meaning. Thus, subject indicators serve as "binding points" whose existence can allow computers to collate information about subjects, so that everything that is known about a given subject is directly available from the perspective of that subject. It doesn't matter which communities use which names for a given subject; all communities can keep using the vocabularies they already use, even though the subjects named in each vocabulary can now be automatically connected with a wealth of materials that have been indexed by other communities who use different vocabularies.
The Reference Model enables instances of extremely diverse knowledge assets to be merged. Even though this merging is in fact driven by semantic identity, it does not require that the machine "understand" the semantics of the subjects around which it is collating information. This is what makes the knowledge alignment paradigm of Topic Maps more scalable and less resource-intensive than approaches that require machines to behave intelligently. The discipline that the Reference Model imposes -- and especially the discipline that every node has exactly one subject, and every subject has exactly one node -- facilitates knowledge aggregation among diverse topic maps. If, for example, Topic Map A and Topic Map B are merged into Topic Map C, whenever a node in Topic Map A has the same subject as a node in Topic Map B, all of the assertions made about both nodes in both topic maps are made about a single node in the resulting merged Topic Map C. If each of the original nodes had assertions connecting them both to any single subject-indicating resource (binding point), the merge can occur automatically, without human intervention.
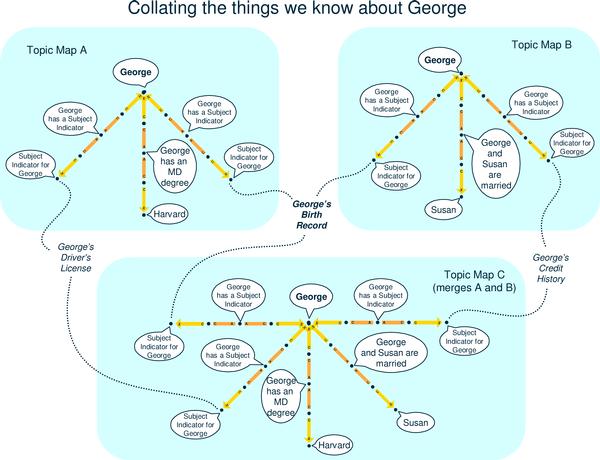 |
The paradigm requires that any two topics that have the same subject must be merged into a single topic; subject indicators make such a situation easy to detect. In both Topic Map A and Topic Map B, the "George" subject has one subject indicator in common: George's birth record. Therefore, in Topic Map C, there cannot be two Georges; they are both known to be one and the same George, and everything that is asserted about George in both A and B are asserted about George in C. George's birth record is the binding point that causes the merging to occur. In this diagram, the subjects of the "Subject Indicator for George" nodes are addressable subjects. An addressable subject is a piece of addressable information considered as itself rather than as anything it might signify. Such subjects are direct properties (here shown as dotted lines) of their node surrogates.
Lossless merging.Conformance to the Reference Model guarantees that users of the original topic maps will find all subjects in the merged topic map exactly where they have learned to expect to find them in the original topic maps. All of the familiar relationships and subjects are still present; the merging process neither changes nor eliminates them. The only difference is that the familiar topic map has been enriched with new subjects and new relationships. While this feature of the Reference Model may seem unremarkable and obvious, it is nevertheless unusual among information interchange paradigms. One of the implications is that, when one topic map is merged with many others, anyone who knows his way around the one topic map will be able to exploit his knowledge when using the others -- even after merging has vastly increased the richness and diversity of the available knowledge.
Self-describing semantics.After diverse topic maps have been merged in a single topic map, a subject in that map may play many roles in many assertions. The assertions may be of different types, and the assertion types may belong to different ontologies. Users of the merged topic map may or may not instantly understand the significance of all of the assertions made about the subject. However, users of conforming systems have direct and convenient access to the ontological information -- the corresponding assertion types and roles, to whatever extent they exist in the topic map -- via the AP and CR arc types.
Ontology-independent merging. The draft Reference Model, which itself makes no ontological assumptions, shows how the merging of topic maps occurs even when they have no ontology, taxonomy, vocabulary or syntax in common, and even when the knowledge assets are maintained under very different editorial conventions and policies. (It is, of course, also true that additional merging may be required by Applications. The SAM's name-based merging rule is one example of such ontology-dependent merging.)
Scaling capacity. The draft Reference Model is extremely simple: four arc types and two built-in assertion types. Each of these six features has a limited number of implications for implementations, and none of these implications prohibits the implementation of systems that distribute knowledge among peer servers that collectively and effectively behave as a single knowledge base. On the basis of the draft Reference Model, distributed systems that can do "lazy" merging -- merging that is done on an ad hoc basis in order to meet an ephemeral user need -- can be created, even if they do not all implement the same Application.
Support for Application design documentation. The draft Reference Model provides sufficient means whereby questions about the processing or semantic implications of any feature of any Application can be asked and answered exhaustively and rigorously.
Acknowledgments
This paper was first presented at XML Europe 2002 (http://www.xmleurope.com/), an IDEAlliance (http://www.idealliance.org/) conference held in Barcelona, Spain, in May, 2002. IDEAlliance has supported the development of the Topic Maps paradigm and standards continuously since 1993.
Graphics by Victoria T. Newcomb.